Knowledge Graphs @ ICLR 2020
👋 Hello, I hope you are all doing well during the lockdown.
ICLR 2020 went fully virtual, and here is a fully virtual article (well, unless you print it) about knowledge graph-related papers at the conference 🚀

Neural Reasoning for Complex QA with KGs
It’s great to see more research and more datasets on complex QA and reasoning tasks. Whereas last year we saw a surge of multi-hop reading comprehension datasets (e.g., HotpotQA), this year at ICLR there is a strong line-up of papers dedicated to studying compositionality and logical complexity: and here KGs are of big help!
🔥 Keysers et al study how to measure compositional generalization of QA models, i.e., when train and test splits operate on the same set of entities (broadly, logical atoms), but the composition of such atoms is different. The authors design a new large KGQA dataset CFQ (Compositional Freebase Questions) comprised of about 240K questions of 35K SPARQL query patterns. Several fascinating points 👀 1) the questions are annotated with EL Description Logic (yes, those were the times around 2005 when DL meant mostly Description Logic, not Deep Learning ⏳); 2) as the dataset is positioned towards semantic parsing, all questions already have linked Freebase IDs (URIs), so you don’t need to plug in your favourite Entity Linking system (like ElasticSearch). So that the model should rather concentrate on inferring relations and their compositions; 3) the questions can have several levels of complexity (mostly corresponding to the size of a Basic Graph Pattern and filters of a SPARQL query).
🔖 The authors apply LSTMs and Transformers baselines to the task and surprisingly find out that all of them fail along the generalization criteria (and correspondingly built train/val/test splits): accuracies are below 20%! This is a serious challenge for KGQA aficionados, we need new ideas 💪

Cohen et al continue the Neural Query Language (NQL) and differentiable KB agenda and present an approach for neural reasoning over large-scale knowledge bases. The authors present Reified KB where facts are represented as sparse matrices (COO format, for instance) in a way that encoding a fact takes six integers and three floats (much less than typical 200-float KG embeddings). The authors then define matrix operations over neighbourhoods suitable for multi-hop reasoning. Such an efficient representation allows storing huge KGs directly in GPU memory, e.g., Freebase dump of WebQuestionsSP of 13M entities and 43M facts fits into three 12-Gb GPUs 💾. Moreover, it is possible to reason over the entire graph when doing QA instead of generating candidates (often this is an external non-differentiable operation). ReifiedKB was evaluated on several KGQA tasks (MetaQA, WebQuestionsSP, and one custom) as well as on the link prediction task, and actually performs quite well compared to current SOTA approaches in those tasks. (We could use some illustrations of the approach, but there are none in the paper, sorry :/ )
Actually, this work is good example why reject-if-not-SOTA (a great blog post by Anna Rogers) should not be a universal metric for paper acceptance, otherwise we might lose a great deal of conceptually new approaches. By the way, check the review on another ICLR 2020 work Query2Box on differentiable querying in the post of Sergei Ivanov dedicated more to Graph ML advancements.
🔥Dhingra et al rely on the similar conceptual framework from the above work of Cohen et al (well, William W. Cohen is a co-author of both 😃) and propose DrKIT, an approach for Differentiable Reasoning over a Knowledge Base of Indexed Text. The architecture might look a bit sophisticated, let’s break it down to particular steps. 1️⃣ First, given a question (that might require multi-hop reasoning) an entity linker produces a set of entities (Z0 in the picture below). 2️⃣ The set of entities is expanded to a set of mentions (represented as sparse matrix A) using a pre-computed index (say, TF-IDF). 3️⃣ On the right side, the question is passed through a BERT-like encoder and forms a dense vector. 4️⃣ All mentions are also encoded through a BERT-like encoder. 5️⃣ The scoring function that measures relevance score of mentions, entities, and question, is computed with the Maximum Inner Product Search (MIPS) algorithms and yields Top-K vectors. 6️⃣ The matrix A is multiplied with Top-K options, and, finally, 7️⃣ the result is multiplied with another sparse matrix B of coreferences (that map mentions to one entity). This constitutes one-hop reasoning step and is equal to following extracted entities along their relations in a virtual KB. 🧙♂️ The outputs can be further used in the next iteration, so repeat N times for N-hop tasks!
Moreover, the authors introduce a new slot-filling dataset based on Wikidata (adopting SLING parser for constructing the dataset), evaluate DrKIT on MetaQA and HotpotQA (catering for HotpotQA is a conceptually different task). Very strong work, overall 💪

🐕 Focusing on HotpotQA, Asai et al introduce Recurrent Retriever: an architecture for open-domain QA which learns to retrieve reasoning paths (chains of paragraphs) in a differentiable manner. Traditionally, RC models employed some off-the-shelf retrieval model to obtain possible candidates and only then executed the neural reading pipeline. Recent approaches aim at making retrieval differentiable as well, thus turning the whole system into an end-to-end trainable model ➡️. First (1️⃣), all paragraphs in the whole (English, obviously) Wikipedia are organized in a graph where edges represent hyperlinks between paragraphs and target pages, e.g., for Natural Questions the size is about 33M nodes and 205M edges, whereas for HotpotQA introductory paragraphs only comprise a graph of about 5M nodes and 23M edges. 2️⃣ The retrieval part employs an RNN that is initialized with a hidden state h0 obtained after encoding a question q along with a candidate paragraph p. Those candidate paragraphs are first generated via TF-IDF and links from the graph (left-most part of the illustration below). 3️⃣ The BERT [CLS] token of the encoded (q,p) pair is fed into an RNN which should predict the next relevant paragraph conditioned on the previous ones. 4️⃣ Once the RNN yields a special [EOE] token, the reader module gets the path, re-ranks them and applies a typical extraction routine.
The authors employ beam search and negative sampling to be more robust to noisy paths and better highlight the relevant paragraphs in the path. Recurrent Retrieval achieves impressive 73 F1 points 👀 on the full wiki test setup of HotpotQA and performs well on SQuAD Open, Natural Questions Open setups where your candidate space is the whole Wikipedia. The code is published, so everybody is encouraged to try and see how it works! 📖

🧮 Let’s talk complex numerical reasoning where you need to perform math operations like count, sort, and arithmetics over a given paragraph to answer a question. An example might be “Who kicked the longest field goal?” given a context “…Jaguars kicker Josh Scobee managed to get a 48-yard field goal…with kicker Nate Kaeding getting a 23-yard field goal…”. So far there are only two datasets for this task: DROP (SQuAD style with at least 20 numbers in a paragraph) and MathQA (shorter questions that require longer computation chains, rationale, answer options). So there is not much KG here, but still an interesting semantic parsing task. There are two papers on this topic.
Chen et al introduce the Neural Symbolic Reader, NeRd (pun intended 🤓) and Gupta et al work on Neural Module Networks (NMNs). Both approaches consist of the reader and RNN-based decoder that yields an action (operator) from a pre-defined Domain Specific Language (DSL). ⚖️ The principal difference that makes NeRd more advanced is in more expressive operators and simpler decoder that builds a compositional program. NMNs, on the other hand, model each operator with tensors interaction, so you’d need to hand-craft more customized modules for more specific tasks. 🛠 Further, the authors of NeRd performed a significant effort to build a corpus of possible programs for the training set for weak supervision, and employed the Hard EM algorithm with thresholding to filter out spurious programs (the ones that give a correct answer based on incorrect assumptions). 🏎 As a result, NeRd achieves 81.7 F1 points and 78.3 EM points on the DROP test set, whereas NMNs are evaluated against about 25% of the DROP data that answerable by their modules and achieve 77.4 F1 and 74 EM points on the DROP dev test. An example program built by NeRd for our example above would be executed as “ARGMAX( KV(‘Josh Scobee’, 48), KV(‘Nate Kaeding’, 23)) = ‘Josh Scobee”. 💪 This is a considerable advancement over 47 F1 baselines and much closer now to the human level of 96 F1.

KG-augmented Language Models
As discussed in the previous posts, there is a clear trend on infusing knowledge into large-scale language models. 📈
This year at ICLR, Xiong et al propose a new training objective in addition to predicting [MASK] tokens: a model is asked to predict whether the entity has been replaced. The pre-training Wikipedia corpus is therefore processed to replace Wiki entity surface form (label) based on its hyperlink with another entity of the same type. The type information is taken from Wikidata (👋) based on the P31 instance of relation. As in the illustrating example below, in the paragraph about Spider-Man the entity Marvel Comics can be replaced with DC Comics and it is the task of the model to predict if it was replaced or not. The resulting WKLM (Weakly Supervised Knowledge-Pretrained Languge Model) is pre-trained with MLM objective (with 5% masking ratio instead of BERT’s 15%) and the new objective which uses 10 negative samples per data point similar to the training process of TransE. The authors evaluated WKLM fact completion performance across 10 Wikidata relations and find it achieves about 29 Hits@10 rate whereas BERT-large and GPT-2 yield about 16 points. WKLM is then fine-tuned and evaluated on WebQuestions, TriviaQA, Quasar-T, and Search-QA datasets outperforming baselines. 👉 Overall, the components of a solid paper are here: a new simple yet substantial idea, extensive experiments, thorough analysis with ablations.

KG Embeddings: Temporal and Inductive Inference
Large-scale KGs like Wikidata are never static, the community updates thousands facts every day where some facts become obsolete and new facts require creating new entities.
Talking about time, if you want to list Presidents of US, triple-based KGs would allow stating (Douglas Adams, president of, USA) as well as (Donald Trump, president of, USA) . Does it mean that there are 45 presidents of the USA simultaneously? 🤔 To avoid such an ambiguity you need to bypass limits of pure RDF and resort to reification (which almost everybody hates) or employ more expressive models. For instance, Wikidata Statement Model allows to put qualifiers to each statement, in our case with presidents, you can put qualifiers start time and end time to denote a time period during which a given assertion was true. Temporal KG Embeddings algorithms aim at building time-aware KG representations. Time dimension in KG embeddings is a part of a more general agenda on embedding literals like height, length, age and other relations that have numerical or string values.
Addressing new entities: most of existing KG embedding algorithms operate on static graphs where all entities are known — a so-called transductive setup. So when you add new nodes and edges you need to re-compute the whole embeddings from scratch, which is not a prudent idea for large graphs with millions of nodes. In the inductive setup previously unseen nodes can be embedded based on their relations and neighbourhoods which representations we already know. There is a growing line of research dedicated to those topics and ICLR 2020 delivers several interesting papers.
Lacroix et al extend the ComplEx embedding model with new regularization components that account for the temporal dimension within the embedding model. The work is packed with insightful contributions. 1️⃣ The idea is that continuous timestamps like years, days and their numerical properties are infused into regularizers. 2️⃣ The authors propose TComplEx where all predicates have a time property and TNTCompEx where “permanent” properties like born in are treated differently. In the experiments it is shown that TNTCompEx performs better. 3️⃣ The authors introduce a new large dataset based on Wikidata (😉) statements with start time and end time qualifiers, the dataset consists of about 400k entities and 7M facts. On the illustration below you can see how the model scores probabilities of the facts describing Presidents of France: indeed, Emmanuel Macron is scored higher since 2017 whereas François Hollande has higher scores for 2012–2017.

⌛️Furher, Xu et al introduce TGAT: the temporal graph attention mechanism to model graphs changing over time including the inductive setup when new previously unseen nodes can be added together with new edges. The idea is based on the Bochner’s theorem from the classical harmony analysis - TL;DR the time dimension can be approximated with a temporal kernel of Fourier transforms. The time embedding is concatenated with standard inputs like node embeddings and all are fed into the self-attention module. So far, TGAT was evaluated on standard transductive and inductive GNN tasks with single-relation graphs (not multi-relational as KGs), but TGAT still shows impressive performance increase 📈. I’d hypothesize that the theory can be further extended to support multi-relational KGs!

Going back to the traditional transductive KG embedding setup:
-GNN? Yes!
🤨-Multi-Relational? Yes!
🤔-Builds embeddings of relations? Right!
👀-Suitable for KGs? Yes sir!
🤩-And for node/graph classification tasks as well? YES.
All those goodies are brought to you by Vashishth et al and their CompGCN architecture. Vanilla Graph ConvNets and message passing frameworks consider graphs with untyped edges and often do not build edge embeddings at all. KGs are multi-relational graphs and having edge representations is crucial for the link prediction task as for the query (Berlin,?,Germany) you’d want to predict capitalOf , not childOf for instance 🤷♀️. In CompGCN, an input KG is first enriched with inverse relations (common practice recently) and self-looping relations (for GCN stability). CompGCN follows the encoder-decoder approach where a graph encoder builds representations of nodes and edges, and then a decoder obtains a score for some downstream task like link prediction or node classification. Node representation is obtained aggregating messages from neighbouring nodes counting incoming and outgoing edges (Wi, Wo on the illustration, and those self-loops) where interaction functions model (subject, predicate) pairs. The authors tried additive (TransE-style), multiplicative (DistMult-style) and circular-correlation (HolE-style) interactions. Edge representations are updated through a linear layer after aggregating node messages. You are pretty much free to choose any decoder you want (🌿☘️🌹🌸): the authors applied TransE, DistMult and ConvE decoders. CompGCN consistently outperforms R-GCN in link prediction and node classification tasks, as well as performs on par with other SOTA models. The best performing CompGCN uses a circular correlation-based encoder with a ConvE decoder.

Last, but not least, Tabacoff and Costabello consider a probability calibration of KGE models. In simpler terms, if your model predicts some fact is true with, say, 90% confidence, it means the model has to be correct 90% of the times. However, usually it is not the case, e.g., on the illustration below it is shown that TransE tends to return smaller probabilities (a bit “pessimistic”).

The authors adopt Brier score to measure calibration, employ Platt scaling and isotonic regression to optimize the calibration score, and suggest strategies for sampling negatives samples in typical link prediction scenarios where “hard negatives” are not given. Good news everyone! 🎉 You can calibrate a KGE model and ensure it would return reliable results. This is a very good analysis and the outcomes suggest that you can actually rely on the KGE model to the extent of its confidence in industrial tasks.
Entity Matching with GNNs
We briefly discussed the problem of entity matching in the previous AAAI’20 post. Integrating different graphs (including KGs) you often have multiple representations of the same real-world entity described with different schemas. Entity matching helps to identify such similar entities: previously it was a tedious mappings curation job, and recently more ML algorithms appear that leverage the graph structure and do not require writing rules. It’s great to see that ICLR 2020 moves the field even further!
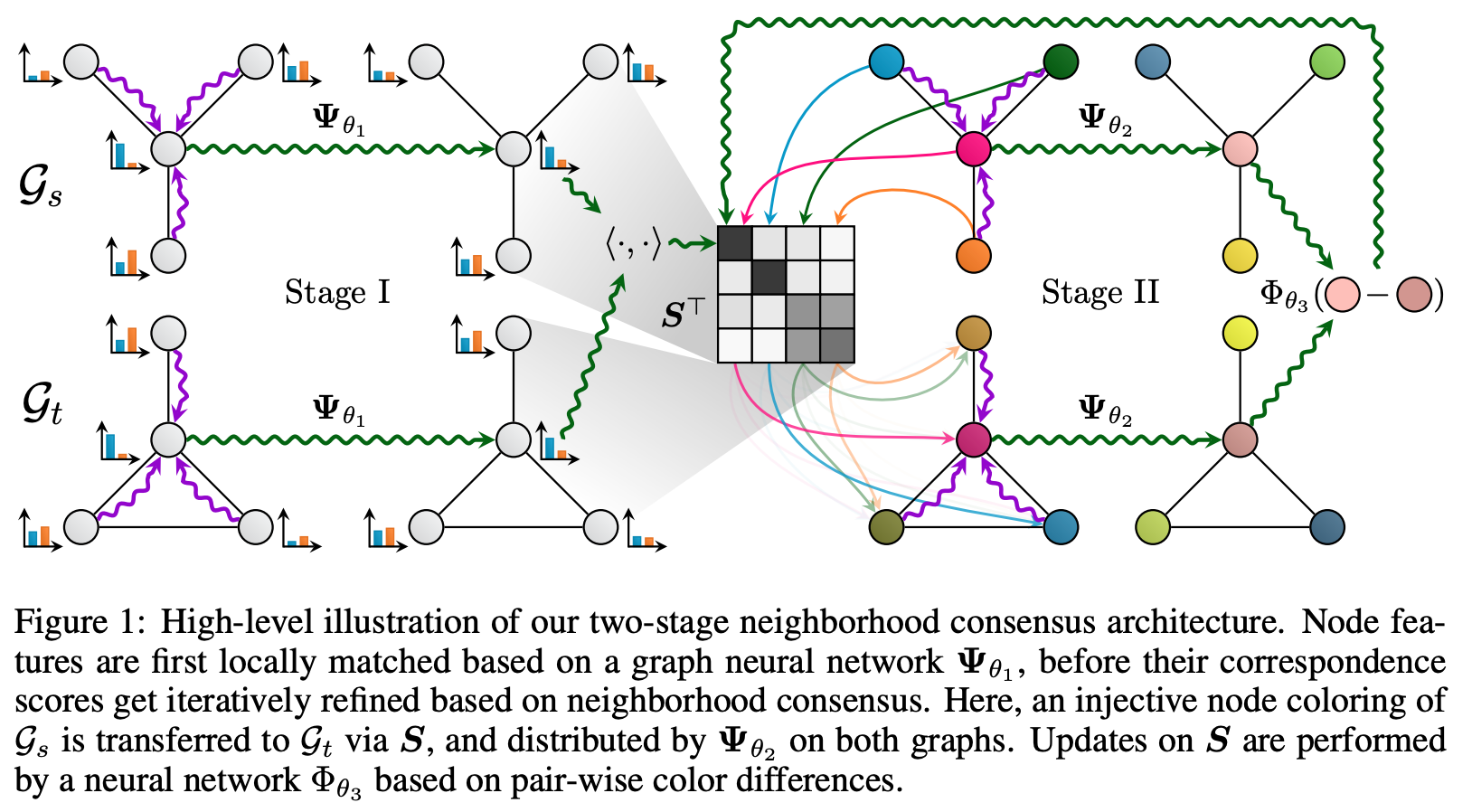
🔥 Fey et al introduce the Deep Graph Matching Consensus (DGMC) framework which consists of two big stages (see the illustration below). 1️⃣ Two graphs, source and target, Gs and Gt respectively, are passed through the same GNN (with the same parameters denoted as psi_theta1) in order to obtain initial node embeddings. The soft correspondences matrix S is obtained multiplying node embeddings and applying the Sinkhorn normalization. You can use any GNN encoder which suits best to the task. 2️⃣ Then, the authors apply message passing (which can also be seen as graph colouring) for the neighbourhoods (some net denoted as psi_theta2), and finally compute the distance between source and target nodes (via psi_theta3): this distance denotes our neighbourhood consensus. DGMC was evaluated on a wide range of tasks: matching random graphs, matching graphs for object detection tasks, and finally, matching English, Chinese, Japanese, and French versions of DBpedia. 🤔 Interestingly, DGMC yields very good results while dropping relation types, so that source and target KGs become essentially single-relational.
Do we really need then to consider all that property type and restriction semantics if we already have 90+% of Hits@10?
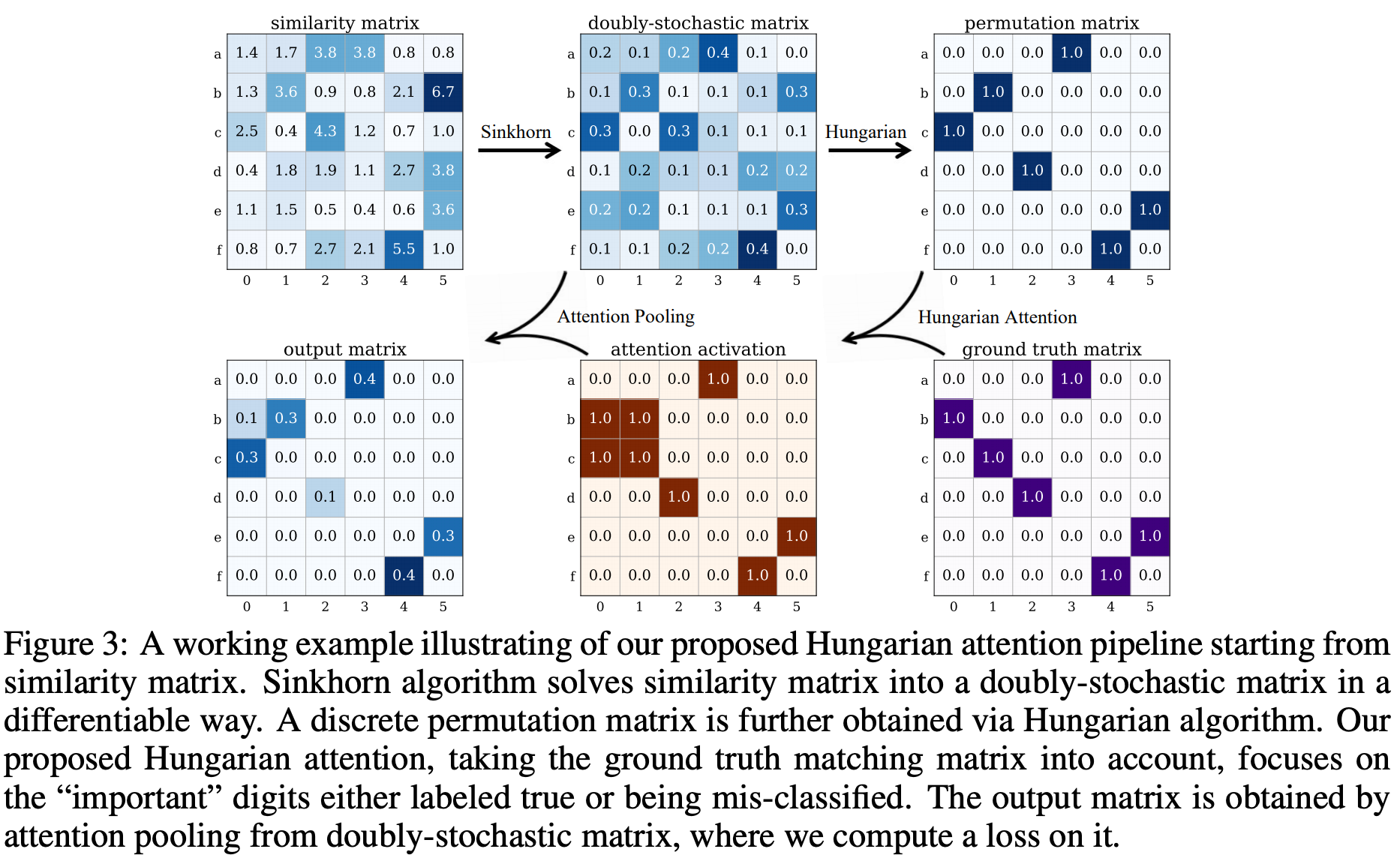
Yu et al present their deep graph matching framework which has two distinctive features: it specifically aggregates edge embeddings, and introduces a new Hungarian attention. The Hungarian algorithm is a classic method for the assignments problem, but it is not differentiable. So the authors generate a network structure according to the output of a black box with this algorithm and propagate the flow further. The Hungarian attention intuition is depicted below. 1️⃣ The initial step is similar to DGMC: some graph encoder generates node and edges embeddings and the similarity matrix is passed through the Sinkhorn normalizaiton. 2️⃣ Here is the main difference: the resulting matrix is fed into the Hungarian black box (instead of the iterative message passing as in DGMC) that produces a discrete matrix. 3️⃣ Compared with the ground truth via the attention mechanism, we get the activations map which is then processed to obtain a loss. The authors evaluated the approach only on CV benchmarks, but it would be interesting to see the runtime on KGs as the Hungarian algorithm is O(n³) 😉
⚔️ Bonus: KGs in Text RPGs 🔮
Interactive Fiction games (like text RPGs Zork) are pure fun 😍 especially in the moments you explore the world and type something weird and wait for the game’s reaction. Ammanabrolu and Hausknecht present a new work on Reinforcement Learning in IF games and employ KGs there all the way to model state space and user interactions.

For instance, having dozens of templates and hundreds of words in a vocabulary it is not feasible to try all possible permutations. But when you maintain a KG of seen objects and, say, your inventory, the agent has drastically less options and is thus more successful advancing the game faster.
In the proposed encoder-decoder model Knowledge Graph Advantage Actor Critic (KG-A2C) the encoder employs GRU for textual inputs and builds graph embeddings with Graph Attention Nets. Further, the graph mask of seen objects is used in the decoder stage. KG-A2C can play 28 games from the benchmark!
Soon they will play computer games better than us meatbags.


